

Introduction
Deduplication is a cool technique that some admins use when it comes to saving storage space. No wonder. By deduping, you can gain some extra storage even without deleting anything. Everyone seems to use it, but how does that thing, actually, work? In this article, I’ll look under dedupe hood to understand better its operating principles. Why one may need this? You see, you always can make the most of things once you understand how they work. I believe this principle to apply to almost everything! So, here’s why I examine such a common storage optimization technique as deduplication in this article.
True, that’s up to you to dedupe or not. Today, I won’t discuss whether you need deduplication at all. Here’s a good article on this matter.
What deduplication is?
Deduplication is a data compression technique for eliminating data copies by replacing them with pointers to the original data. This technique enables to win some extra disk capacity by reducing the overall space taken by data while preserving both data location and integrity. In other words, you’ll still be able to access the copy of your data by the same path after dedupe, but there will be more free space on the disk.
I believe the image below to describe the nature of deduplication accurately.
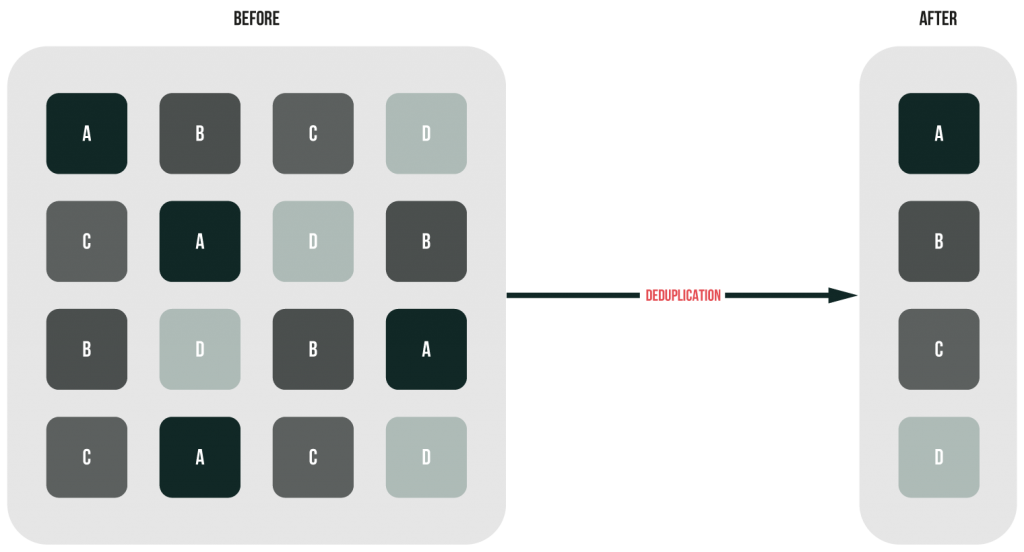
Now, as you know what dedupe is, I’d like to say that it’s a pretty broad topic. Actually, there are three approaches to data deduplication: file-level, block-level, and byte-level. Also, there are multiple ways to handle the process. Let’s discuss everything!
File-level deduplication
File-level deduplication, as it comes from the name, enables to replace file duplicates with the pointers to original ones. For this reason, that approach is often referred to as single-instance storage.
Let’s see how it works. File deduplication compares a new file with the already existing ones by checking its attributes against an index. If the file is unique, it is stored, and its index is updated. If it isn’t, only a pointer to the original one is stored. In this way, only one instance is saved while its subsequent copies are replaced with pointers.
As it is the highest deduplication level don’t expect it to be efficient that much. For more dedupe efficiency, you need to go deeper.
Block-level deduplication
Block-level deduplication segments data stream into segments – blocks of the custom size – checking whether each block has ever been encountered before. It uses a hash algorithm to generate a unique identifier for each block. If the block is original, it’s written to the disk, and its identifier is stored in an index. If an arriving block matches the existing one, only a pointer to the unique block remains. And, that’s how you win some disk space!
Byte-level deduplication
Byte-level deduplication performs a byte-by-byte comparison of arriving data streams to the already stored data. This approach delivers higher accuracy and storage saving efficiency than methods I discussed above as it operates at the lowest level. On the other hand, byte-level deduplication consumes more compute resource than any other approach I discussed above.
How is dedupe actually handled?
Based on where data are deduped, there are several ways to handle that process:
- Source deduplication
- Target deduplication
- Post Process deduplication
- Inline deduplication
- Global Deduplication
To understand dedupe, let’s discuss all those techniques one by one.
Source deduplication
Source deduplication is the removal of the duplicated data on the VM or host before they get transmitted to some target. This dedupe type works through the client software that communicates with the backup target comparing the new blocks of data.
There’s really nothing special about this method. So, I believe the image below to describe good enough how it works.
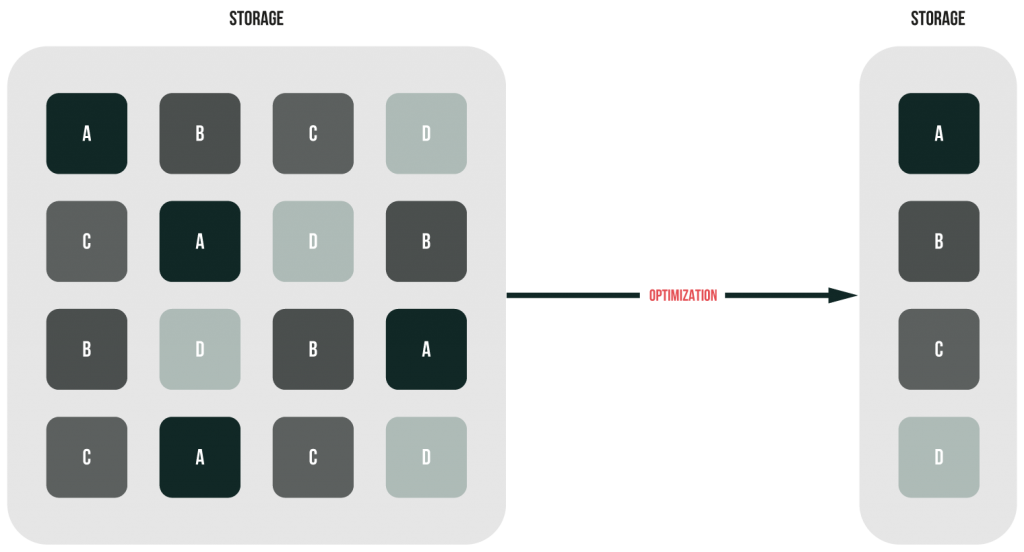
Now, let’s talk about the pros and cons of the source deduplication. As data are deduped right on the host or disk, this dedupe type does not consume networking bandwidth that much. Also, there’s no additional hardware is required for increasing storage efficiency. On the other hand, source deduplication may be slower and even make your host perform a bit sluggish once you deal with considerable amounts of data. These performance drops, in their turn, may increase the backup time.
Target deduplication
Target dedupe removes data copies when they are transmitted through some intermediate host between the source and target. This method is used by the intelligent disk targets and virtual tape libraries. Unlike the source deduplication, target dedupe doesn’t consume the source host resources. Thus, there will be no performance drops when you deal with the large amounts of data! Still, you need some extra hardware for this method. That host storage should be able to cope with the considerable workloads as data arrive from multiple sources. Also, there is a good risk of the network overload as large amounts of data are transmitted all the time.
Here’s how this method works.
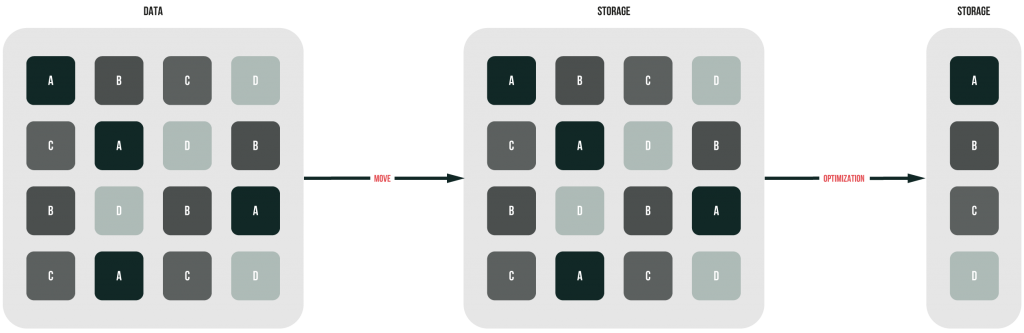
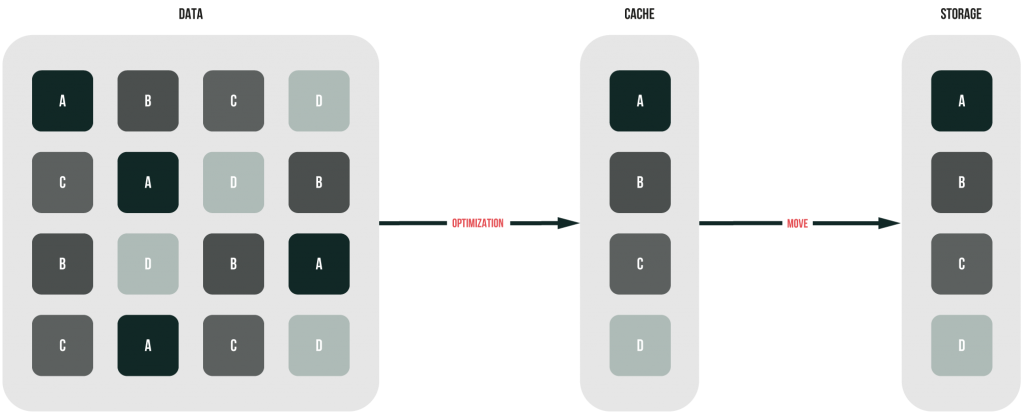
Post-Process deduplication
Post-process dedupe (sometimes referred to as asynchronous deduplication) caches all data before deduplicating them. Subsequently, the cache gets flashed to the storage where storage optimization itself occurs.
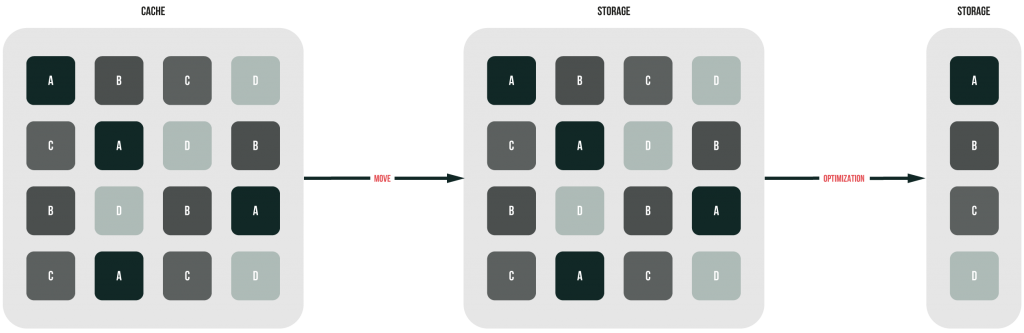
So, all data are initially written to the disk cache “as they are” and get deduped afterward. Data are deduplicated independently from copying, so you can copy and dedupe data without having disk performance compromised. Looks wonderful, doesn’t it? But, there’s a small thing about this method: CPU utilization is a bit higher than during any other method discussed above.
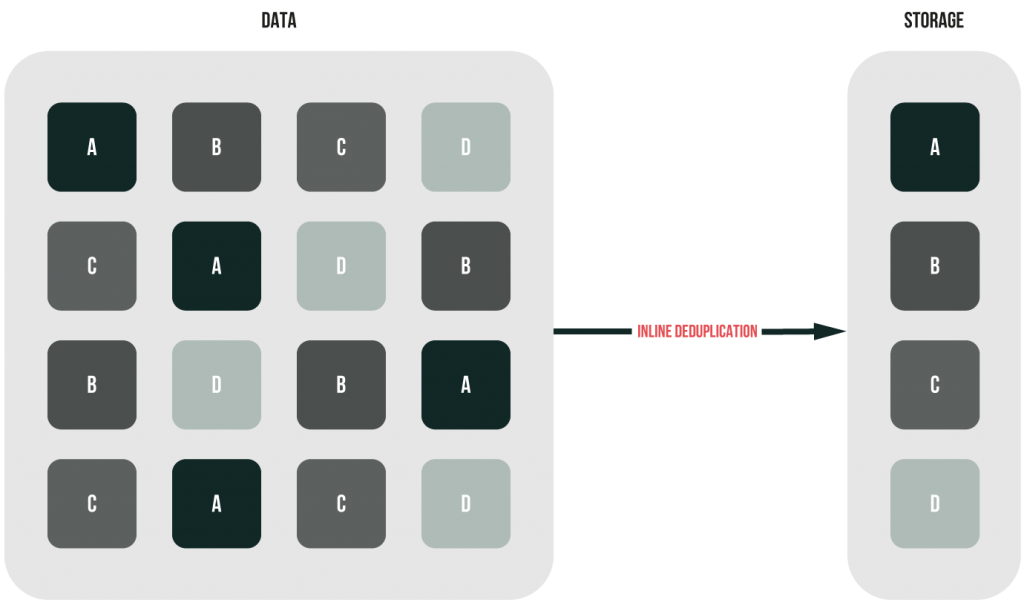
Inline deduplication
During inline dedupe, redundancies are removed while data are written to the storage. By running algorithms that check hashes, the inline dedupe software checks arriving data against the already existing in the storage. If there’s no match, data can be stored. The initial data get optimized, are cached, and, finally, are written to the disk. In this way, this approach is good for your SSDs as it reduces remarkably the number of writes. On the other hand, this dedupe technique utilizes CPU, so there may be some lags.
Global Deduplication
Now, as you know all deduplication techniques, I believe that’s time to talk about something big: global deduplication. Global deduplication is a block-level deduplication technique that helps to prevent redundancies when writing data to many hosts (target dedupe). It can be implemented on multiple clients (source dedupe) as well. Global dedupe increases the data dedupe ratio – the ratio of the saved capacity to the subsequently occupied storage. Also, global dedupe enables to balance loads, delivers high availability, and provides retention policies flexibility. Regarding all these benefits, no wonder that this dedupe technique is commonly used in large and complex environments.
Now, let’s look at how this method works. Let’s say, data are sent from one node to another. The second node, in its turn, is aware of the data copy on the first node and does not make an extra copy. This approach is more efficient than single-node dedupe that dedupes only data residing on that node.
Conclusion
Today, I discussed how deduplication works. I believe this article to be handy for some nerds and guys who want to learn more about deduplication. Also, I hope you to understand the process better on the whole now.
